From a job offer link to a tailored CV in 60 seconds.
AI SaaS
Own product (zlozcv.pl)
2026
Solo Founder · Full-Stack · AI
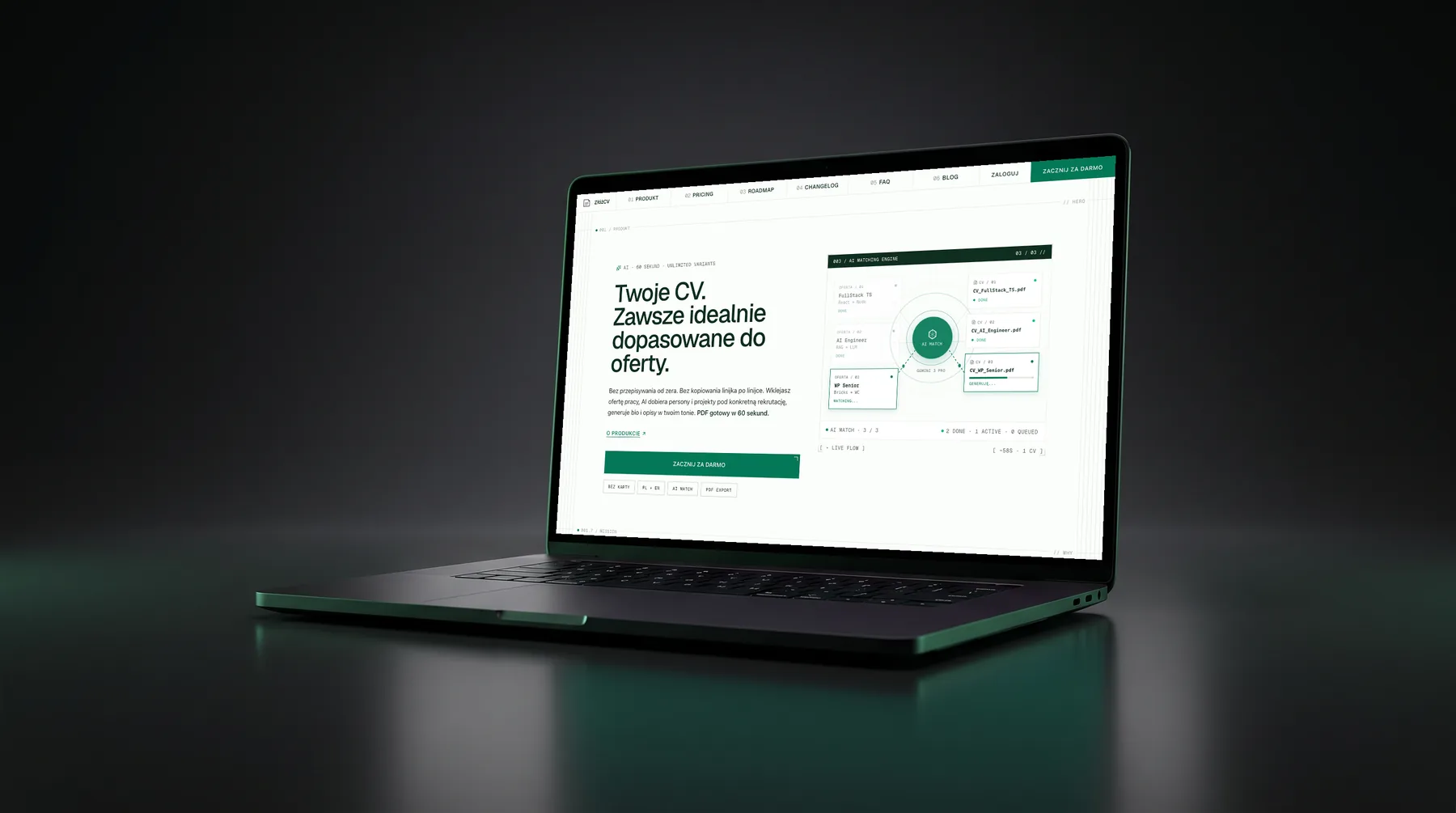
At a glance
An AI CV builder that turns a job offer into a tailored, ready-to-send CV in about a minute - one profile, a fresh version for every job.
01 - The problem
Five rewrites a week just to keep your CV honest.
Every job seeker I know runs the same loop: open last week’s CV, swap one skill for another, reword the summary, cut the projects that don’t fit this employer, save it under yet another “final” filename, and send. Three days later a better offer shows up and you’re editing the same file again, hoping you didn’t already tell this company you knew something you don’t.
Readable by recruiters, friendly to the automated screening systems, and a genuine fit for the role - three goals that fight each other every time. Generic CV builders handle the formatting and ignore the matching. Asking a chatbot to “rewrite my CV for this job” invents skills you don’t have. The result: half an hour of copy-paste per application before you even click send, and a folder full of slightly different files you no longer trust.
ZłóżCV exists because the obvious thing had to be built: one place that holds your real projects and experience, one paste-the-offer step, and about a minute later a CV that’s tailored, factual, and won’t let you down on the interview call.
02 - The vision
Paste the offer. Get the CV. - everything else is plumbing.
Three product principles drove every decision:
- One source of truth. Your projects, experience, skills and career angles live in one place. Every CV is a view of that profile tuned to a specific offer - not another file in the “final” folder. Edit a project description once and every future CV picks it up.
- Matching is the product. The headline number isn’t “CV downloaded”, it’s how well the CV fits the offer. The AI reads the job posting, separates the must-haves from the nice-to-haves, picks the right angle, scores every project against the role and writes a summary in your voice. The document is the artifact; the matching is the value.
- About a minute, or it’s broken. Read the offer, pick the angle, score the projects, write the summary, produce the CV - the whole thing has to finish inside one coffee sip. Any longer and the user is back to copy-pasting in Word.
03 - Who it’s for
One profile, four different CVs - same person, four different stories the role wants to hear.
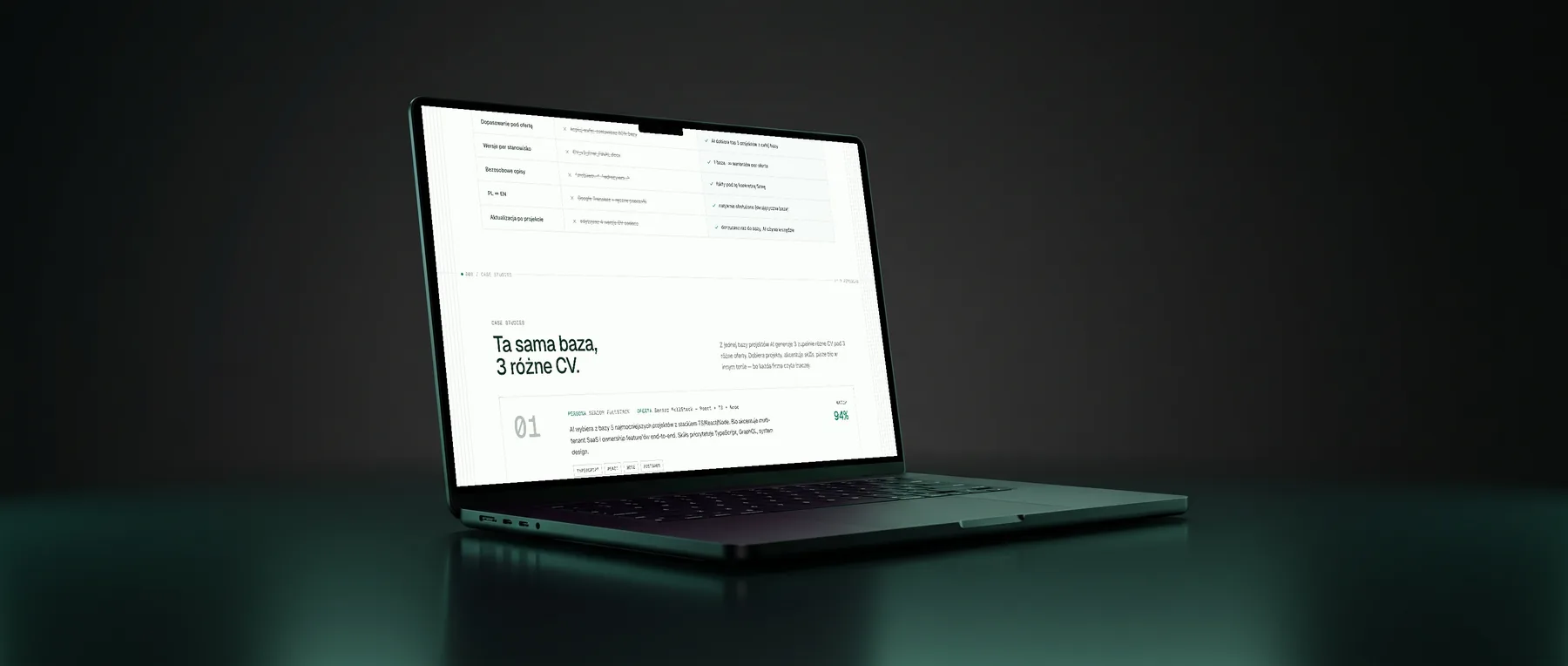
Senior FullStack · 94%
Offer for a full-stack web role. The CV leads with large web-app work and end-to-end ownership, and the skills most relevant to the role move to the top.
AI Engineer · 91%
Offer for AI and machine-learning work. The summary switches to an AI voice, and projects about model work and reliability get highlighted first.
WordPress Senior · 89%
Offer for WordPress and e-commerce. The summary swaps in an agency voice: client work, deadlines and site performance, while the AI-flavoured material drops off the page.
Frontend Mid · 87%
A demo profile: the same source data produces a mid-level frontend CV. Backend depth is dialled down and interface craft gets the spotlight. Same data, a completely different story.
04 - Technology & the challenge
A modern stack, one genuinely hard problem.
ZłóżCV runs on a modern web stack - a fast marketing site, a private dashboard where you keep your profile, and a small cloud setup that quietly handles accounts, payments and email. Google’s Gemini does the thinking: it reads the job offer, works out what the employer really wants, picks the right angle from your profile and writes a summary in your own voice, all in about a minute.
The genuinely hard part was trust. It is easy to make an AI write a flattering CV; the difficulty is making sure it never claims a skill you don’t have. If something isn’t in your profile, it doesn’t make it into the CV - so what you hand to a recruiter is always tailored and always true. Getting the whole flow to feel instant, and the finished document to look pixel-perfect on paper, was where most of the work went.
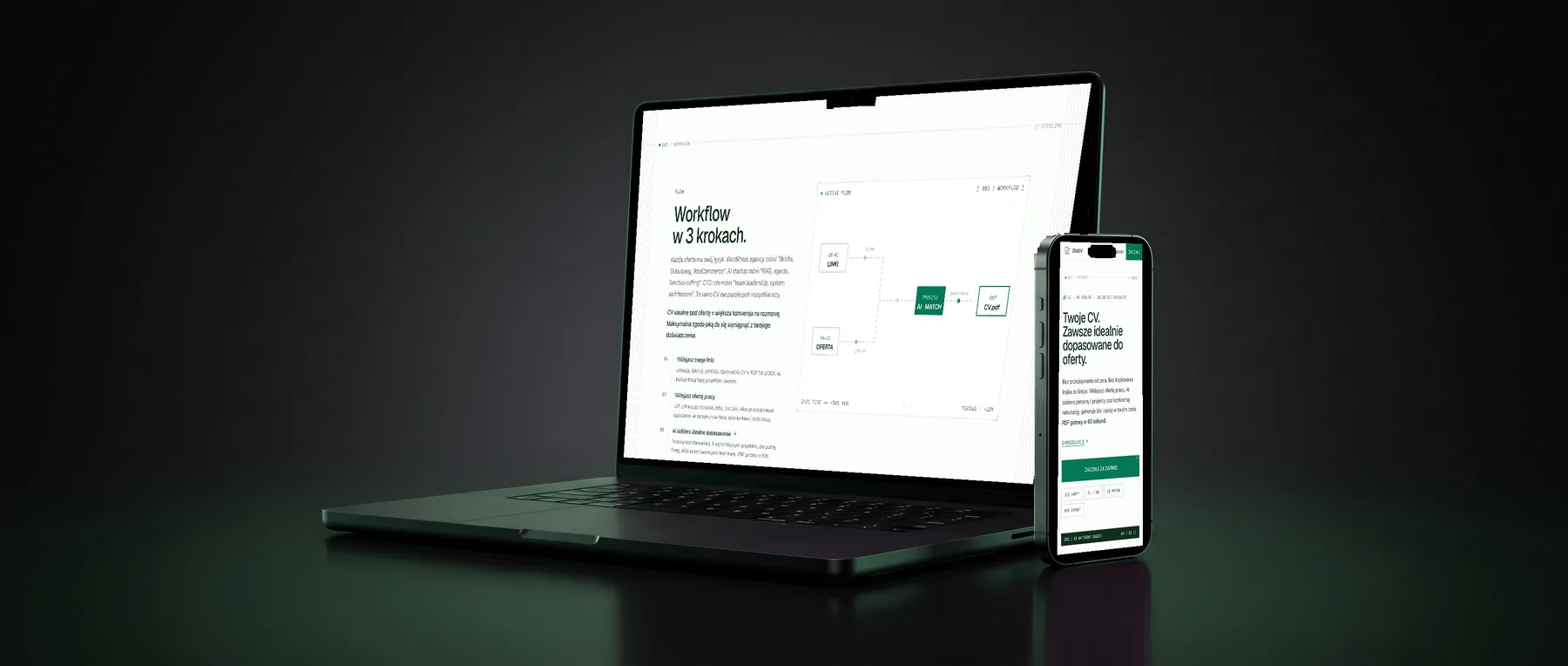
05 - The workflow
Three steps. One tailored CV.
Paste your profile link (or use the browser add-on). Paste a job offer link or a screenshot - the AI reads the must-have skills, the tech focus and the seniority. It then picks the right angle, scores every project against the role, drafts a summary in your voice and produces the finished CV. Average run: under a minute, with no invented skills - if it isn’t in your profile, it isn’t in the CV.
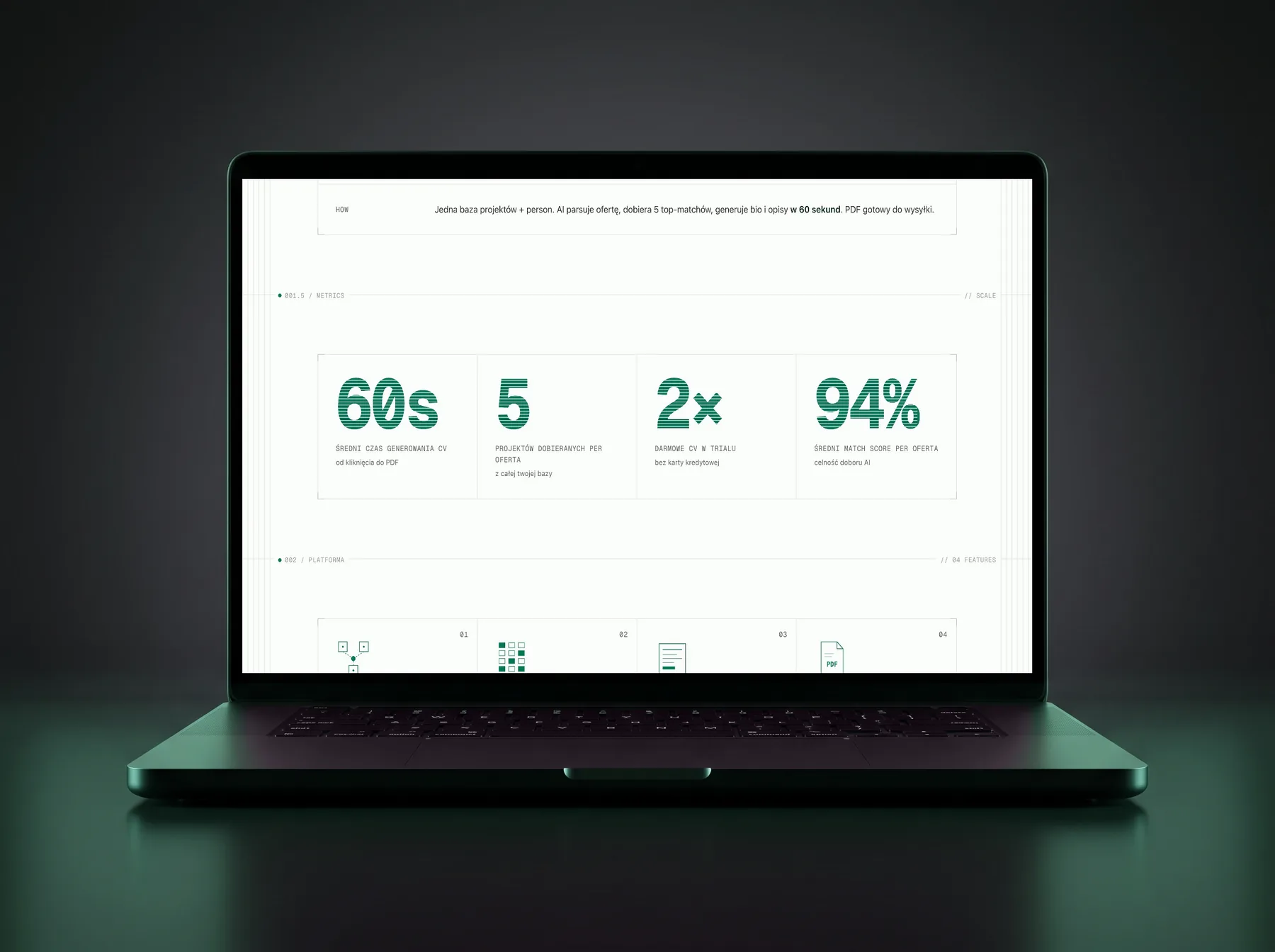
06 - Feature highlights
Four things on the landing, two more hiding behind the dashboard.
The metrics block on zlozcv.pl - about a minute to generate, five projects picked per offer, two free CVs without a card, and a strong average match score - is the public face. The two features below are the quiet infrastructure underneath.
+ Role-aware project descriptions
Each project can carry several ready-made angles, in Polish and English. The generator picks the one that fits the role, and falls back to a default summary if there isn’t a better match. One project entry, endless role-appropriate versions.
+ Browser add-on
A floating “Generate CV” button on the big Polish and international job boards. It signs in against the same account as the website, so there is nothing extra to set up or maintain.
07 - Results
Live, paying, build-in-public.
ZłóżCV is in production on zlozcv.pl with active paying subscriptions at 29 PLN/mo, the same profile also powering my own CV site, and a build-in-public counter on the landing showing every generation as it happens. I use it myself on every job application I send.

Like what you see?
Let’s build the next one.
From a blank page to a working product - AI, automation, full-stack engineering. Get in touch and let’s talk about your idea.